Every second counts when it comes to detecting, diagnosing, and resolving network incidents, yet many teams still find themselves stuck in reactive mode, drowning in alerts, manually writing scripts, and managing tickets across disconnected systems. This is where Selector and Itential come in.
Together, Selector and Itential deliver a powerful, enterprise-ready solution that closes the loop between detection and action. Real-time observability, paired with policy-driven automation, enables the instant resolution of incidents with no manual intervention.
For a closer look at the integration, view our webinar, “From Insight to Impact: Closing the Loop on Network Ops with Selector and Itential” featuring Selector’s Head of DevRel, John Capobianco, and Itential’s Director of Tech Evangelism, William Collins.
AI-Driven Observability Meets Automated Remediation
The Selector + Itential integration creates a closed-loop, event-driven workflow designed for modern infrastructure teams. Here’s how it works:
- Selector detects the issue: Our platform ingests telemetry, logs, metrics, and events from across your environment, using AI and machine learning to correlate anomalies, identify root causes, and trigger automated workflows.
- Itential launches remediation: Itential’s platform receives the trigger and executes a policy-based remediation workflow – automatically validating, enforcing policies, and tracking every step along the way.
- End-to-end automation: Whether it’s resetting a port, updating a config, or spinning up additional resources, Itential ensures that changes are validated and documented, with no human lag or guesswork.
This is observability and automation working in sync – from detection, to decision, to deployment.
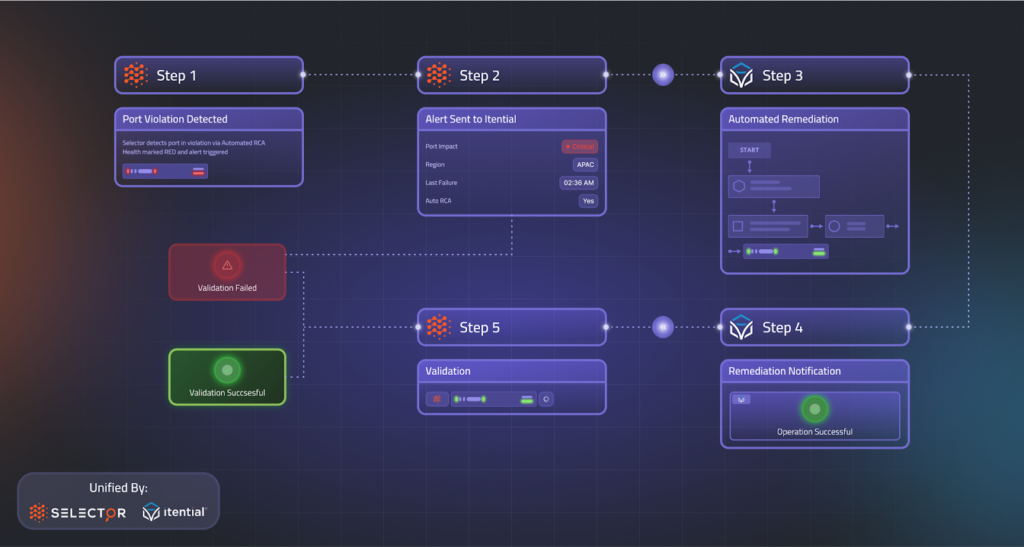
A Real-World Example: Automated Port Reset
Imagine a scenario where a critical port goes down:
- Selector detects the anomaly, correlates it with related events, and identifies the failed port.
- Itential is triggered via API, launching a predefined workflow.
- A ServiceNow ticket is automatically created, maintaining the integrity of your ITSM processes.
- Itential enriches data from inventory sources like NetBox, runs pre-checks, and validates the failure.
- Automated remediation is executed (e.g., the port is reset).
- Post-checks confirm success, updates are synced, and the ticket is closed.
- Selector and Itential maintain complete visibility, ensuring the issue is resolved completely.
All of this happens without a single manual script, ticket update, or context switch – dramatically reducing mean time to resolution (MTTR).
Why Enterprises Trust Selector + Itential
- AI-driven event detection: Turn noisy alerts into clear, actionable root causes.
- Closed-loop automation: Automated, policy-driven fixes with full validation and audit trails.
- Faster MTTR: Move from hours of investigation to seconds of resolution.
- Seamless integration: Built to work with your existing toolchain – ServiceNow, NetBox, APIs, and more.
- Scalable for complex environments: Designed for carrier-grade and large enterprise networks.
Built for Modern Infrastructure
Whether you’re running large enterprise IT, telco networks, or hybrid cloud environments, Selector and Itential give you the tools to shift from reactive firefighting to proactive, automated operations. With this joint solution, you can detect issues in real-time, trigger automation instantly, validate and track every action, and resolve incidents before users are even aware of them.
Discover how Selector and Itential can help your organization move from detection to resolution in real time. View the webinar today.
To stay up-to-date with the latest news and blog posts from Selector, follow us on LinkedIn or X and subscribe to our YouTube channel.