Nowadays, network operations engineers, planning engineers, and technology engineers are using a plethora of collaboration tools such as Slack and Microsoft Teams to share and collaborate on valuable information. The increase in distributed and virtual work environments — accelerated by the COVID-19 pandemic — has given rise to ChatOps for network operations, where collaboration happens directly in these messaging tools. Operations engineers now need to react quickly and communicate synchronously and asynchronously to identify the root cause of network problems.
The Challenge: Switching Between Tools Slows Teams Down
Traditionally, operations engineer had to leave their collaboration tools to access other applications and dashboards to find the data they needed. They would then copy and paste information back into Slack or Teams to share with the team — a time-consuming and inefficient workflow.
While some observability tools can post notifications into Slack or Teams, it’s still not the most effective or interactive method for network operations ChatOps.
Selector Brings Network Operations ChatOps to the Next Level
Selector has redefined ChatOps for network operations. By leveraging natural language queries and the Selector Analytics platform, any operations engineer can simply ask the platform a question within Slack or Teams and receive immediate answers in the same channel.
Key advantages include:
- Answers are instantly visible to all team members in the channel.
- No need to switch between tools or copy-paste data.
- Multiple teams can interact with the Selector platform from their own collaboration channels, enabling cross-domain and cross-team collaboration.
Faster Troubleshooting and Reduced MTTR
Operations teams need to track Mean Time to Detect (MTTD) and Mean Time to Repair (MTTR) to assess network health. Both metrics improve when information flows quickly from the network to engineers and across teams.
By integrating Selector with Slack or Microsoft Teams, your teams can:
- Access real-time insights directly in your collaboration tool without logging into other interfaces.
- Use natural language queries to pull data even if they don’t know S2QL, Selector’s query language.
- Share insights instantly for faster decision-making and reduced MTTR.
Benefits of Selector’s Network Operations ChatOps Integration
- Get answers where your team works — Slack or Teams — without workflow disruption.
- Lower the information barrier with natural language queries.
- Speed up detection and resolution by improving collaboration and context sharing.
- Enable proactive, ChatOps-driven network operations for distributed teams.
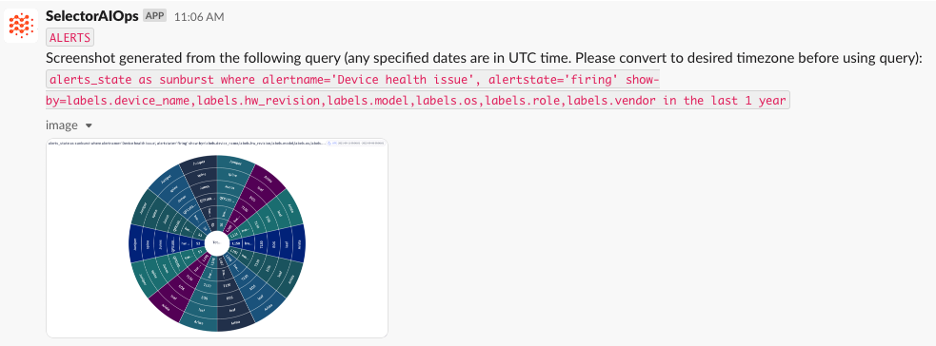
See ChatOps for Network Operations in Action
Below are several screenshots of this unique feature in Slack and Microsoft Teams:
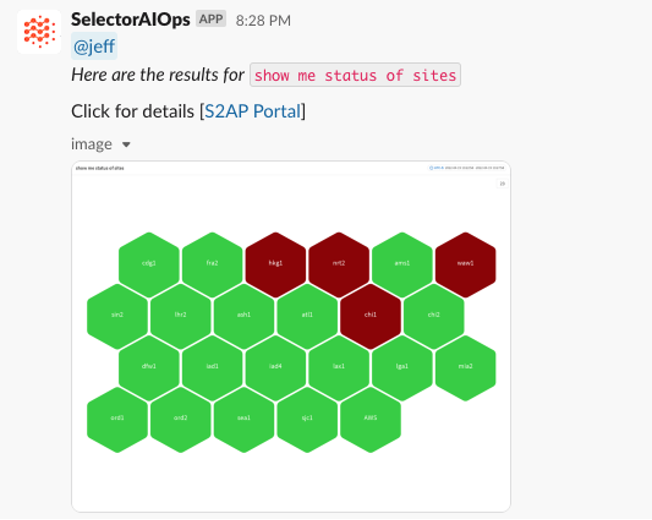
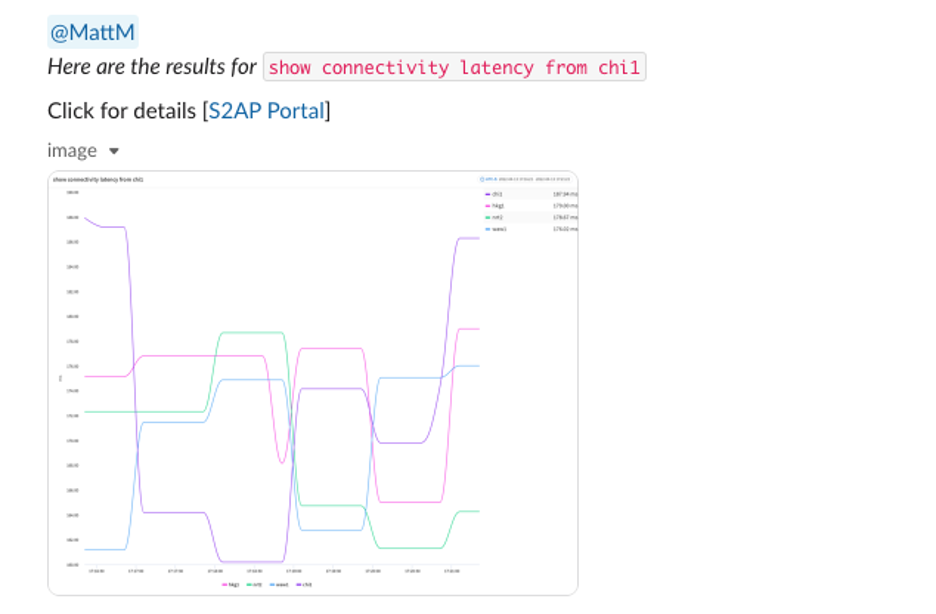
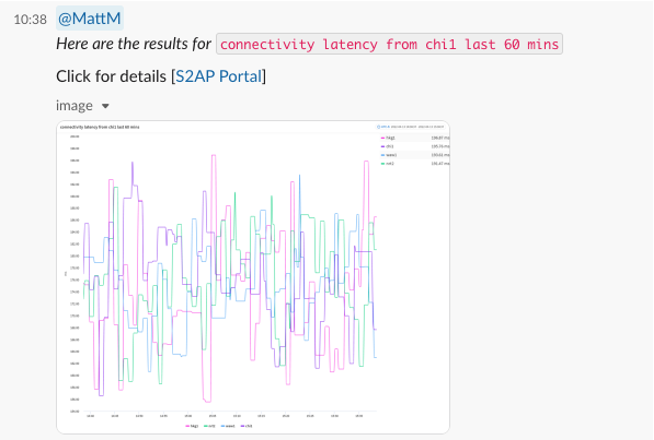
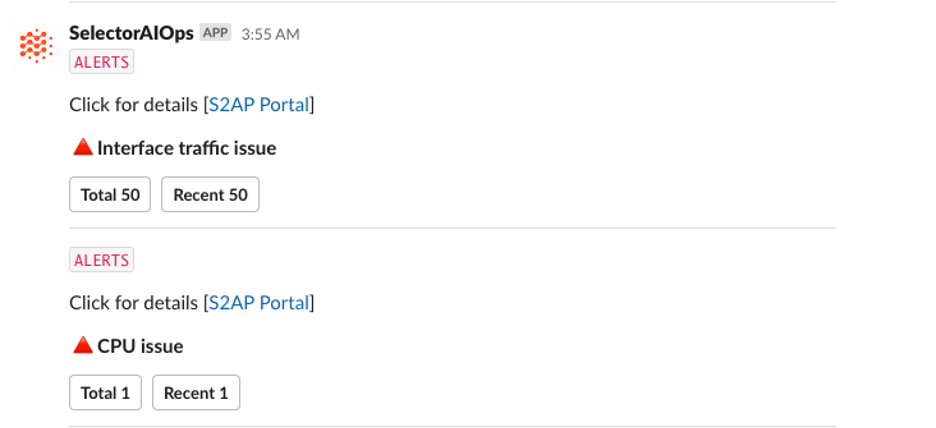
Interested in learning more about this feature? Contact us today for a free demo!


