In our previous post, we explored the urgent need for intelligent automation in network automation, specifically how the Model Context Protocol (MCP) enables AI agents to dynamically discover and interact with the necessary tools. But access to tools is only part of the equation.
To truly operate autonomously in complex environments, agents need not only connectivity but also intelligence. They must be able to reason through conditions, make decisions based on context, and take action that aligns with operational goals.
This is where the real power of AI agents emerges. And it starts with how they think.
How Agents Think: The ReACT Model
At the core of modern AI Agents is a loop of Reasoning and Acting, often referred to as the ReACT model. This model enables agents to evaluate a situation using logic and context, select the most suitable tool or course of action, and then execute that action, often through MCP-enabled integrations.
Let’s bring this to life with a practical example:
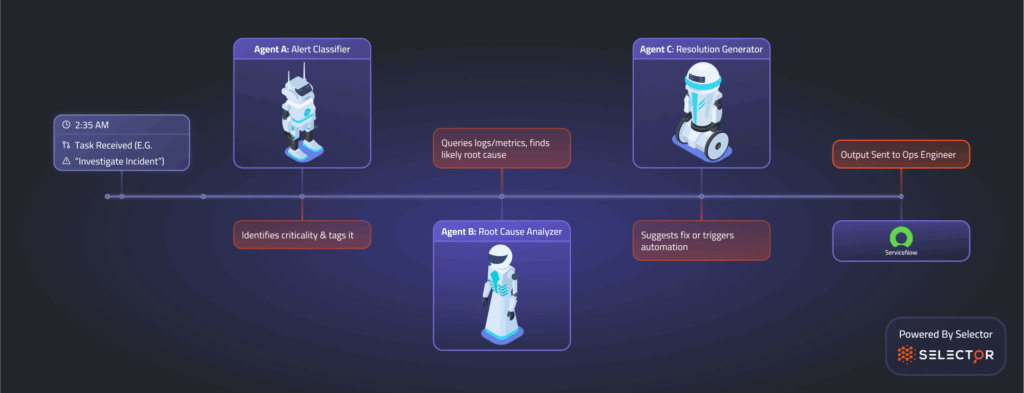
Imagine a core routing path is suddenly experiencing high packet loss. An AI agent built on the ReACT model might begin by querying telemetry data across affected interfaces. It detects a pattern: a specific link has degraded significantly in the past 10 minutes. The agent evaluates recent configuration changes, network topology, and traffic patterns, ultimately concluding that a misconfigured quality of service (QoS) policy is likely the cause.
Rather than waiting for human intervention, the agent:
- Selects the appropriate remediation tool via MCP
- Adjusts the QoS settings through the network controller API
- Monitors the results in real-time to confirm the issue is resolved
- Documents its actions in the incident management platform
This is a step beyond simple automation. This is intelligent decision-making, a marked shift from predefined responses to context-aware reasoning.

LangGraph: Managing Complex Workflows
While ReACT defines how agents make individual decisions, modern networks require agents to manage multi-stop, conditional workflows. That’s where LangGraph comes in.
LandGraph is a framework that helps orchestrate the logic behind these complex processes. It allows agents to:
- Route between tools dynamically
- Handle branching decisions (e.g., “If X is true, do Y. Otherwise, try Z”)
- Incorporate loops, error handling, and fallback strategies
- Work in coordination with other agents or services
By using LangGraph, agents gain the flexibility to handle real-world scenarios where outcomes are rarely binary and rarely predictable. It transforms the agent’s mind from a single-track executor into a flexible problem-solver that can adapt its behavior based on current conditions.
Pydantic: Trusting the Data
For agents to make sound decisions, they need trustworthy data. However, in enterprise networks, data is often messy, with inconsistent formats, missing fields, unexpected values, and incomplete responses being common.
Enter Pydantic – a framework that validates and parses structured data so agents can work with clean, reliable inputs. When an agent retrieves information from a tool (like a REST API via MCP), Pydantic ensures:
- The data conforms to expected schemas
- Missing or malformed values are flagged
- The agent receives strongly typed objects to reason with
This reduced the risk of faulty actions based on bad or incomplete data. It also simplifies the internal logic that agents need to handle, allowing them to focus on decision-making rather than data cleaning.
A Glimpse Into The Future: Agent2Agent Collaboration
So far, we’ve focused on how individual agents operate, but what happens when multiple agents start working together?
That’s the promise of Google’s Agent2Agent (A2A) initiative – a model for enabling autonomous agents to communicate, share knowledge, and coordinate actions to solve complex problems more efficiently.
In a network operations context, this opens the door to powerful collaboration between specialized agents. For example:
- One agent monitors performance metrics
- Another handles security enforcement
- A third is responsible for policy compliance
When an anomaly is detected, these agents can coordinate: the first detects the issue, the second checks for security implications, and the third initiates the proper policy-driven response. All without a single manual touchpoint.
While A2A is still in its early stages of development, it reflects a broader trend toward multi-agent systems that mimic human collaboration, combining expertise, sharing information, and taking coordinated action.
From Intelligence to Implementation
AI agents that can reason, make decisions, and collaborate represent a significant leap forward for network operations. However, without a practical way to deploy them, even the most advanced agent frameworks remain hypothetical.
That’s why the next step is crucial: implementing these ideas in real-world settings. Selector has taken these principles and translated them into a working system – one that’s modular, production-ready, and built for real network teams.
In the final post of this series, we’ll explore how Selector’s MCP server makes intelligent automation actionable, enabling fast integration, scalable workflows, and the flexibility needed to handle modern network demands. Make sure to follow us on LinkedIn or X and subscribe to our YouTube channel to be notified of new posts.