In today’s distributed systems, visibility isn’t optional — it’s critical. If a DNS resolution slows down, an API responds incorrectly, or a regional network segment drops packets, customers need to know immediately. Our Synthetics feature was built for that purpose: it runs a suite of predefined network probes (like ping and traceroute) and pushes the resulting metrics — latency, jitter, packet loss — into a metric store for monitoring and alerting.
That’s worked well for standard use cases. But over time, one thing became clear: customers needed more flexibility.
Suppose a customer wanted to check DNS latency to an internal domain, validate TLS handshakes, or simulate a multi-step API transaction. These types of checks didn’t fit into the fixed list of built-in probes. Supporting them meant updating the underlying agent — a process that’s slow, inflexible, and often out of sync with customer needs.
So we asked: What if customers could write and run their own probes — without needing to wait on us?
The What: Introducing Custom Synthetics
Custom Synthetics is a new capability that lets customers define their own network and service checks in Python, upload them to the platform, and have them run just like our built-in probes. The resulting metrics flow through the same telemetry pipeline and end up in the customer’s metric store, ready to be charted, queried, and alerted on.
This gives customers full control over what to measure, how to measure it, and what constitutes success or failure — all without needing to deploy a new agent version or submit a feature request.
Here’s how it works in practice:
- Customers write a Python script that performs a check — for example, making an HTTP request, resolving a domain, or verifying the response from a service.
- They upload the script through our API or UI, along with any configuration like scheduling frequency or target endpoints.
- The platform runs the code in a sandboxed environment on a regular schedule.
- The script outputs metrics in a standard format.
- The system collects and forwards those metrics to the customer’s metric store, where they behave like any other time series — ready for visualization and alerting.
This design means customers get the best of both worlds: the flexibility to define their own probes, and the reliability of a first-class monitoring pipeline.
How It Works: Behind the Scenes
The technical foundation of Custom Synthetics focuses on security, flexibility, and observability. Here’s a breakdown of the core architecture:
- Execution sandbox: Each customer-defined probe runs in a restricted, containerized environment. The runtime enforces limits on memory, CPU, network access, and execution time to protect the platform and other workloads.
- Simple authoring model: Probes are just Python scripts. There’s no DSL to learn or complex setup to manage. Customers bring their logic; we handle the rest.
- Standardized output: The script emits structured results (metrics, tags, errors), which are automatically parsed and sent to the customer’s metric store.
- Central scheduling and orchestration: Probes are scheduled and executed from a control plane, with logs and results captured centrally for debugging and observability.
This system lets customers move fast, experiment freely, and maintain visibility across increasingly complex networks and services — all without sacrificing control or safety.
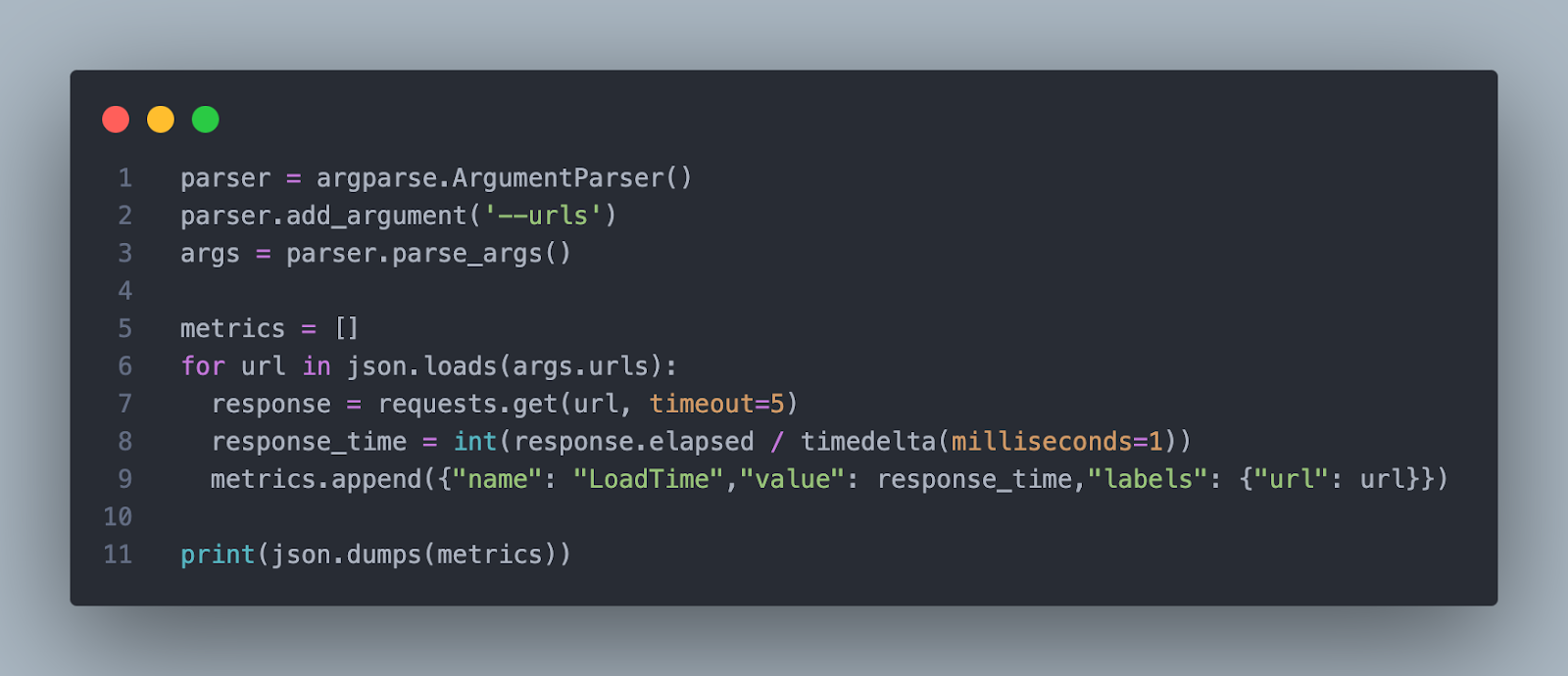
Sample Custom Synthetic Probe:
This probe takes in a list of URLs, and generates the LoadTime metric for each of those URLs.
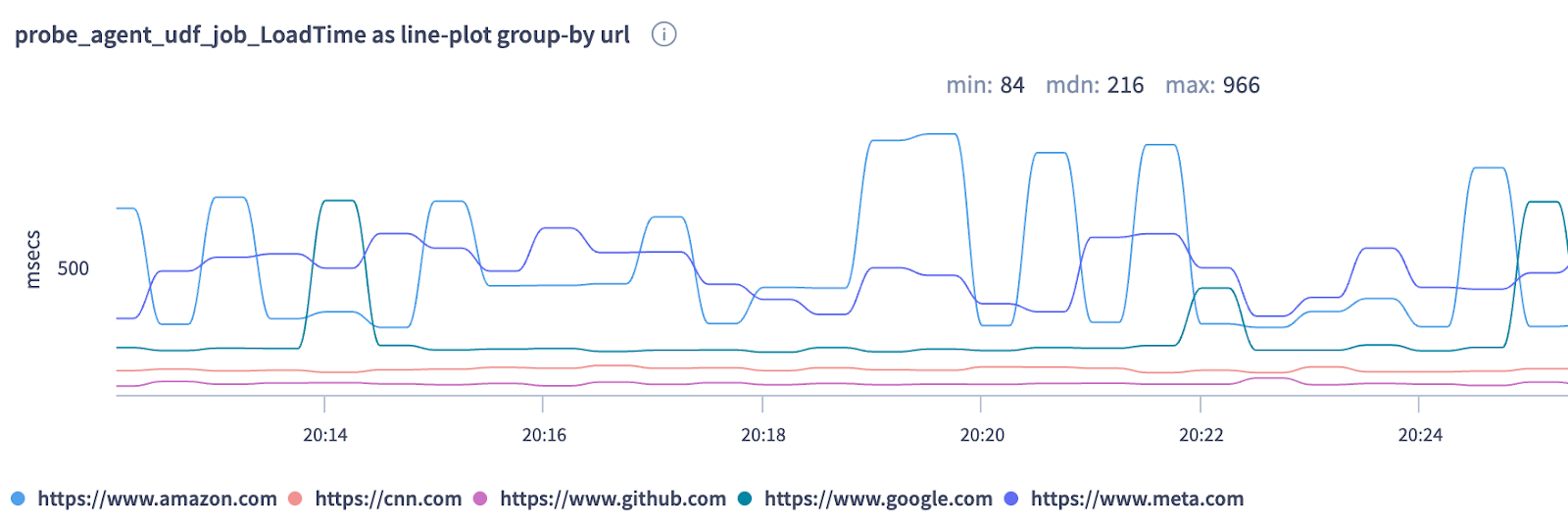
Once this probe is uploaded and attached to a compute resource along with the associated configuration parameters like the URL list, it will be executed at a certain interval and the metrics generated would be shipped to a metric store. One could then visualize these metrics on dashboards, or configure alerts and other workflows. Following is one such visualization where the above probe was configured with URLs www.amazon.com, cnn.com, github.com, google.com, and meta.com. Here we have load time for each of the URLs as a time-series.
Use Cases: Monitoring Without Limits
Here are just a few examples on how custom synthetics could be leveraged:
DNS Resolution Monitoring
Many customers manage private DNS zones or depend on third-party resolvers. A custom probe can resolve critical domains from different locations and emit latency and success/failure metrics, helping detect regional DNS degradation or failures.
Authenticated HTTP Checks
Built-in probes can’t always deal with real-world scenarios like token-based authentication or POST requests with payloads. With a custom probe, customers can simulate full API requests, validate response bodies, and verify SLA compliance with business-critical services.
TLS Handshake Timing
For services requiring secure connections, customers can create probes that measure the time it takes to complete a TLS handshake — a useful indicator of certificate issues or misconfigured CDNs.
Multi-Step Logic Checks
One could build a probe that performs a series of dependent API calls to simulate a full user journey — checking that the right objects are returned and that the data remains consistent across services.
These kinds of probes are incredibly valuable — and until now, they required workarounds or custom tooling. With Custom Synthetics, they’re native and first-class.
Why We Built It This Way
There were easier paths: we could have added more built-in probes, or created a limited DSL for customers to configure predefined actions. But we believe in building tools that scale with customer creativity, not limit it.
That’s why we chose Python — it’s accessible, expressive, and familiar to most engineers. Combined with strict sandboxing and a simplified output model, it lets customers go from idea to live metrics in minutes, without compromising system safety or observability.
From an engineering perspective, this meant investing in:
- Safe execution environments that isolate customer workloads while preserving performance and reliability.
- A unified telemetry pipeline that handles both built-in and custom probe outputs the same way.
- Developer experience that balances power with guardrails, so teams can build quickly but safely.
Our goal wasn’t just to make probes extensible — it was to make extensibility feel native.
Observability on Your Terms
Custom Synthetics unlocks a new level of control in monitoring setups. No more waiting for platform updates. No more hacking together one-off tools. Now, when customers need to observe something specific — whether it’s a DNS resolver, a slow API, or a flaky external dependency — they can write a probe and ship it themselves.
All the heavy lifting is handled by the platform. Customers write the logic, we run it securely, and the metrics show up exactly where they should — ready to power alerts, dashboards, and decisions.
Whether you’re a platform team enforcing SLAs, a network engineer debugging regional anomalies, or an application developer catching regressions before your users do, Custom Synthetics gives customers the flexibility they need — without the friction.
Check out the docs, explore real-world examples, and start building your first custom probe today. To stay up-to-date with the latest news and blog posts from Selector, follow us on LinkedIn or X and subscribe to our YouTube channel.