When we discuss networks, we typically envision data packets racing along physical wires like vehicles on a highway. But beneath this visible traffic flows another critical pathway that few recognize: the control plane highway. This unseen infrastructure, where routing information flows between devices, makes the data highway possible. Before user data can flow, millions of paths must be established, creating a parallel network of equally vital importance.
Understanding networks through this dual-highway perspective doesn’t just satisfy intellectual curiosity—it transforms how we approach network design, troubleshooting, and optimization. By reframing our perception to see the control plane as a highway, we unlock powerful new opportunities for network intelligence, where machine learning and AI generate unprecedented analytics, revealing patterns and predictive insights that have remained largely untapped despite the control plane’s decades-long existence.
Reimagining Network Architecture
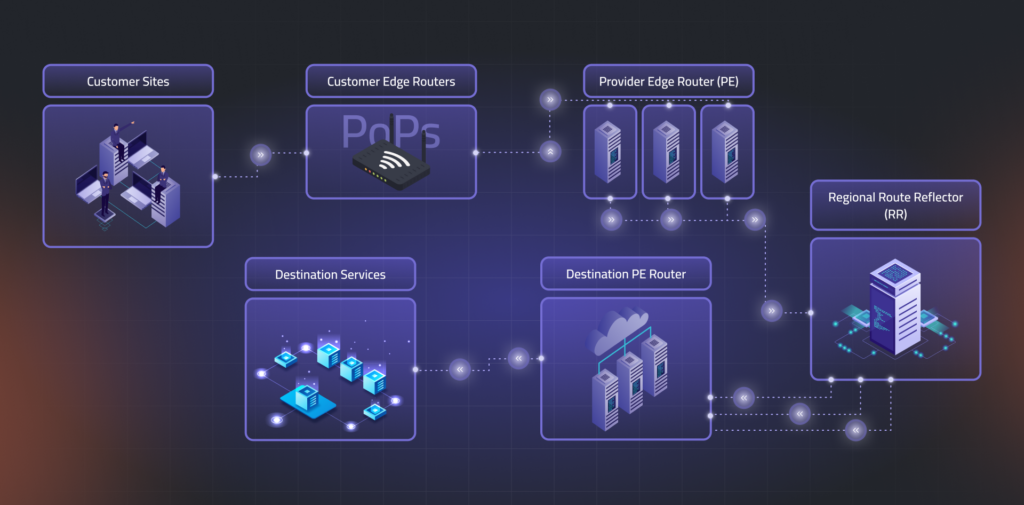
Service providers build networks that connect customers to their services and branch offices using layer-3 VPNs. At the network edge, routes are exchanged, which travel through a system of route reflectors before reaching the provider edge routers closest to each customer location.
Route reflectors (RRs)—physical devices or virtual software—are organized in a carefully designed hierarchy. Network architects group them strategically and split routing tables, so no single RR must store all routes. Operators create specific rules for sharing routes to ensure each customer location gets all the routing information it needs while preventing any individual reflector from becoming overloaded.
When customers connect from various global Points of Presence (PoPs), routing information travels through a carefully designed hierarchy:
- Customer edge routers connect to local provider edge routers
- Provider edge routers communicate with RRs
- RRs exchange information with other RRs (across regions)
- Information propagates to the provider edge routers near destinations
- Finally reaches customers’ local networks
The Control Plane Highway Visualization
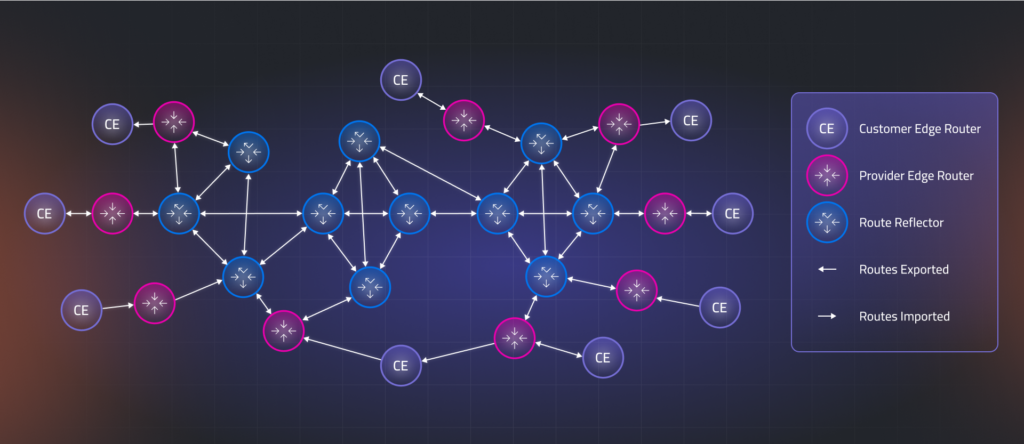
Picture this intricate routing ecosystem as an expansive highway network displayed on a geographic map. Each critical component—customer-edge routers, provider-edge routers, and route-reflectors—appears as a distinct node positioned at its physical location.
Routing information flows along directional arrows between nodes, with the arrow’s thickness proportional to the traffic volume through the number of routes being exchanged.
This customer-specific visualization reveals the complete journey of routing data, from its origins at various entry points to its distribution across all customer locations. The topology showcases the dynamic propagation of routes as they flow through the hierarchical system, highlighting potential bottlenecks, redundant paths, and the efficiency of the route distribution architecture.
Analytics and Insights: The Control Plane Highway Monitoring System
When we visualize the control plane as a highway system, complex routing data becomes intuitively accessible. Instead of being scattered across multiple databases and router tables requiring specialized query language knowledge, information appears as an interactive map with nodes (network elements) and edges (sessions) that anyone can understand.
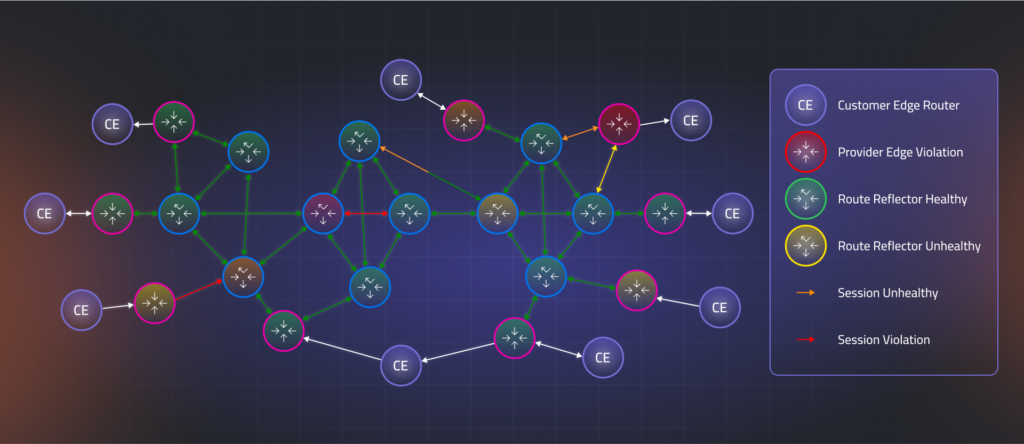
Traffic Control Centers: Monitoring Network Nodes
Every junction on our highway (routers and reflectors) becomes clickable, revealing critical operational data. Like a modern traffic control center, we can instantly see:
- Traffic volume: Routes exported, imported, or reflected
- Junction configuration: Equipment settings and state
- Resource utilization: CPU and memory usage (intersection capacity)
- Customer impact: How much routing table space each customer occupies
- Overall health indicators: KPIs that evaluate node performance
These metrics translate visually into familiar traffic signals: green lights indicate healthy nodes, yellow-orange lights warn of developing issues, and red lights signal violations where route propagation may be incomplete or blocked, preventing customers from reaching all their global Points of Presence (PoPs).
Road Condition Monitoring: Analyzing Connection Edges
The highways connecting these junctions (BGP sessions between network elements) provide equally valuable insights. Clicking on any road segment reveals:
- Traffic patterns: Routes flowing between specific nodes
- Directional flow: Information exchanged in both directions between provider edge routers, route reflectors, and customer equipment
- Connection health: Protocol operational status between node pairs
Traffic engineers monitor road conditions; similarly, our visualization uses color-coding to indicate connection health: green for optimal flow, yellow-orange for concerning conditions, and dark red for critical issues blocking route dissemination. Importantly, since each BGP session typically carries routing data for multiple customers across shared infrastructure, the status of a single edge can reveal broader impacts affecting many customers while highlighting redundant paths that maintain connectivity despite local disruptions.
Patterns, Predictions, and Impact Analysis
The highway metaphor extends naturally to trend analysis and capacity planning. Just as traffic engineers study road usage patterns to anticipate future needs, network operators can visualize:
- Historical traffic trends: Normal export patterns from customer locations
- Anomaly detection: Unexpected spikes or dips in route counts
- Predictive modeling: Forecasting future routing table growth
- Capacity thresholds: Identifying when route reflectors approach saturation points
Since service providers use shared infrastructure for multiple customers, they must ensure that one customer’s behavior doesn’t create “traffic jams” affecting others. Using “what-if” analysis tools, operators can create virtual simulations for each customer, like digital twins, to analyze potential impacts before they occur.
These simulations allow operators to observe how the control plane highway would respond if a customer exceeded current route limits or SLA thresholds: which paths would experience congestion first, how edge colors would shift from green to yellow to orange to red, and where bottlenecks might develop. This virtual environment enables strategic planning for customer growth and SLA management without risking disruption to the production network, allowing operators to test configuration changes, adjust session capacities, or add new RRs while ensuring service level commitments remain intact, all in a safe environment before implementing changes.
Transforming Network Visibility Through Highway Visualization
The control plane highway metaphor transforms network monitoring by visualizing routing information flows as a dynamic system with traffic signals. This gives operators clear visibility while making complex architectures intuitive for all stakeholders. This approach enables proactive management through trend analysis and simulation, ensuring robust control planes as networks grow increasingly complex.
This approach is valuable for service providers and applies equally to enterprise networks, data centers, cloud environments, and any routing ecosystem. It makes the invisible infrastructure that powers our connected world visible and optimized for future challenges.
Request a demo today to see how Selector visualizes the control plane like never before, empowering your team with deep routing insights and predictive analytics. To stay up-to-date with the latest news and blog posts from Selector, follow us on LinkedIn or X and subscribe to our YouTube channel.