In the last eighteen months, Selector has progressively integrated large language models into its operations to a greater and greater degree. We use them in both extractive and abstractive ways, seeking to both interpret natural language effectively and communicate in a way that the most seasoned network engineers might do in the real world. The evolution of the LLM space over this time period, from the models themselves to the tools and frameworks used to work with them, has progressed at a phenomenal pace. Tools that we used initially have already been deprecated or abandoned, new and better ones have sprung up, and we’ve been forced into rapid adoption and rapid migration scenarios along the way. It’s been quite a journey, and we’ve learned a tremendous amount.
Thinking back over the process of building Selector Copilot, our chat style question and answering system that allows you to “talk” to your network, we’ve picked up many valuable lessons, learning both from the pitfalls we managed to dodge and the ones we stumbled into. Copilot is the last step of a vast pipeline of data enrichment and interpretation, stacking layers of increasing insight using traditional machine learning techniques and transformation steps. Each step builds upon the last, bubbling its way up toward the final output – a concise and accurate natural language summary of the state of your network and devices at any given moment. Getting the data to the point where it can be handed off to an LLM requires careful consideration, with lots of opportunities for errors along the way. These are just a few of the most important lessons we’ve learned while integrating an LLM into the Selector app.

1. Overestimating the LLM’s inherent understanding beyond language
Fundamentally, a large language model is good at language. It does not know your data, the particulars of your naming conventions, the topologies in which your devices are organized, or the interconnections between them. It cannot accurately determine root causes, correlate events, or explain why something might be happening in a non-generic way. Given the opportunity, it can and will confidently make up answers that sound reasonable, but are fundamentally inaccurate.
This highlights the importance of data processing using traditional machine learning and transformation methods, so that the final context presented to the LLM already contains the answers being sought. A few examples…
- You cannot pass a list of events and expect it to determine the root cause…the root cause needs to be predetermined and passed to the LLM, as a definitive and deterministic fact. The root cause analysis is where the real work is done, leaving the LLM the simple job of presenting the findings as natural language. I have come to think of the LLM as just another presentation layer. In the same way that we present data as interactive widgets in our web app via a browser, or as a snapshot image using our Slack or Teams interface, we can present our data as a natural language summary.
- Similarly, you cannot pass an LLM a list of device metrics and expect it to determine the status of the device. You must provide the status of the device to the LLM, determined by a rich set of underlying analysis pipelines. At Selector, we use combinations of traditional ML based baselining, statistical modeling, regression models, NER models, outlier detection models, and correlation models (among others) to make these determinations.
Even beyond that, our data passes through several final stages of transformation specific to natural language presentation. This further refines the data in a way specific to how the LLM needs and understands context data. In fact, we go so far as to generate a pseudo-natural language summary using traditional data-processing techniques that serves as a hint to the LLM as to what to report.
Needless to say, what we’ve learned is to leave nothing up for interpretation when it comes to LLM consumption. Especially in mission critical environments, it is imperative to get this part right.
2. Context is King
I remember in my elementary and high school math classes, I’d be given word problems that would include some related, but ultimately irrelevant, facts. These would serve to see if I could filter out the signal from the noise, and not get thrown off by some data points that weren’t part of the final calculations. Inevitably though, I’d get snagged by one of these superfluous nuggets and end up with the wrong answer.
If it can happen to a human, it can happen to an LLM (now that I say that, I may have to give that some additional thought). Regardless, too much and too dissimilar information can lead to some very unexpected responses.
For example, the Selector app is constantly scanning all known datapoints and events, correlating them into records that represent single anomalies. These records are labeled by device, interface, subnet, and so on, allowing us to quickly check a specific entity for issues. Initially, we attempted to scan across the entire collection looking for all anomalies related to an entity, indiscriminate of the anomaly or event type. However, this proved problematic as the LLM would incorrectly connect the dots between these often unrelated anomalies in strange and interesting ways, presenting the user with a confusing and convoluted summary. We’ve since implemented more robust filtering to ensure only genuinely related anomalies are grouped for summarization.
Of course, the best-case scenario would be striking that perfect balance of providing just enough information needed to answer a question, and nothing more. We have employed a variety of techniques toward this end, including:
- Relevance filtering: using semantic similarity to include only the most relevant columns from a dataframe.
- Distributions: Precalculating distribution percentages grouped by a particular field of interest. For example, rather than device and status pairings for thousands of devices, we will precalculate distributions across status, allowing the LLM to report percentage and counts for each status bucket.
- Prioritization: In general, our users are most interested in knowing what is wrong, so we will prioritize records that are in violation of some predefined or autobaselined value, and push records with nominal values to the back.
On the flip side of that, leaving out relevant information can starve the LLM, giving it no choice but to hallucinate and make up an answer. Our prompts always include instructions to report that it can’t determine an answer if relevant data hasn’t been provided, but invariably we see it happen anyway.
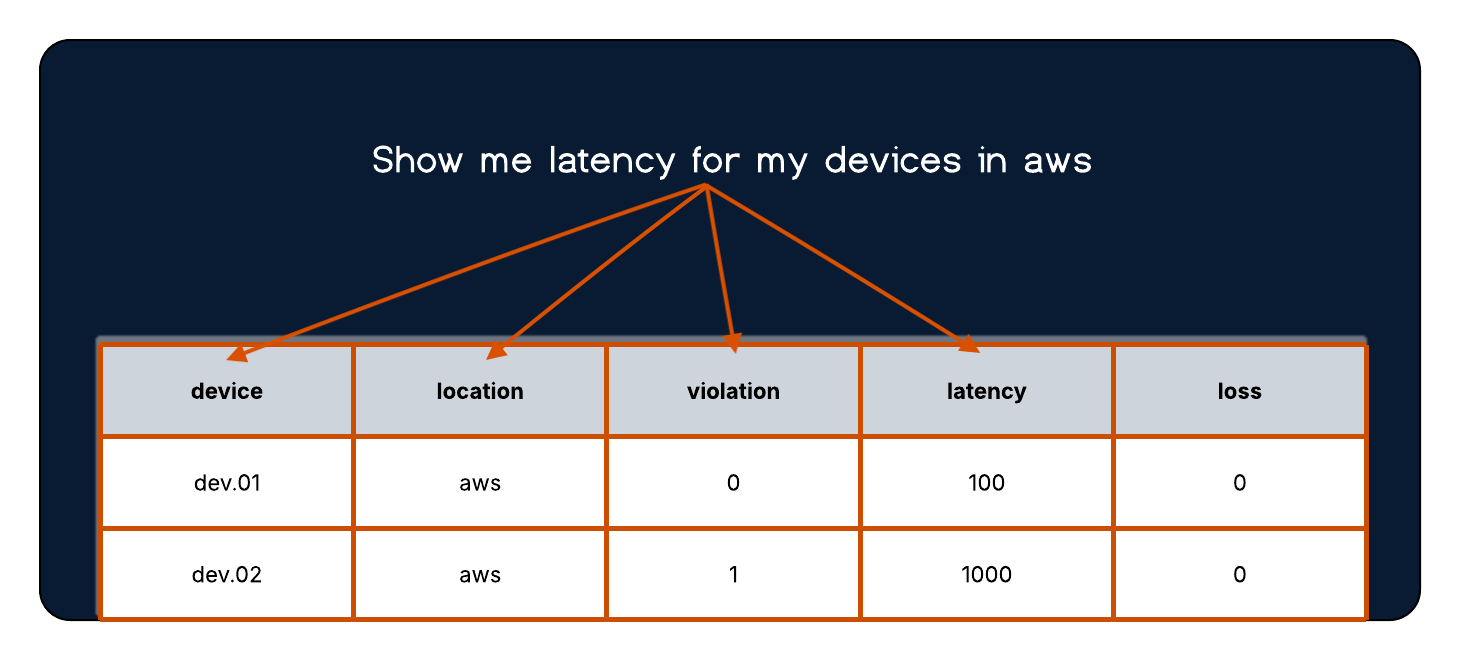
For example, in the early days when token limits were stricter and context windows were smaller, we would indiscriminately strip all numeric values from a dataframe before passing it along to the LLM. When questions such as “What is the latency between device A and device B” were asked, the LLM wouldn’t have the information needed to report the average latency in the given time window. It did have information about whether the latency was within normal limits or was in violation, but the actual value was not present.
Today, we use a rag mechanism that finds the top n columns related to the user’s query and provides only those column values to the LLM. This has allowed us to be more precise in what is given to the LLM, without overwhelming it with superfluous information. These incremental learnings and adaptations we’ve made along the way have made a big difference in both the quality and accuracy of responses.
3. Poor or Vague Prompting
I won’t spend too much time on this one, as it’s pretty obvious. The prompts need a high level of detail. Leave no boundary undefined, provide examples, be specific, and be assertive. Our prompts are highly tuned, and we continually update them in order to address new scenarios and establish new boundaries or expectations. The end result can be quite lengthy, but gives us the kind of result that we and our customers desire. We will continue refining these and adapting these as new models with new capabilities roll out, as our data changes, and as new edge cases are discovered.
Conclusion
So there you have it…certainly not an exhaustive list of things we’ve learned, but absolutely the ones that have resulted in the biggest impact. As I look to the future of Copilot, I can’t help but feel excited about the opportunities ahead. We are looking forward to introducing numerous enhancements in the coming months, including some new and experimental services that rely heavily on the power of Large Language Models. Some of these include natural language to query translation, improved reasoning capabilities, better understanding of conversational context, and movement into the MCP and agentic landscape. These will all, no doubt, come with their own set of challenges, but ones we look forward to tackling head on.
To stay up-to-date with the latest news and blog posts from Selector, follow us on LinkedIn or X and subscribe to our YouTube channel.