Selector is excited to give a sneak peek into new features to be included in our forthcoming Spring Release. This release highlights key innovations focusing on integrated generative AI (GenAI) to enable guided troubleshooting and automated incident remediation. It also includes enhancements to several existing features, such as root cause analysis, native monitoring, and observability capabilities.
Get an in-depth look at how these enhancements drive efficiency through tool consolidation and provide transformative insights into the health and performance of network and IT environments.
Spring Release Highlights
The latest Selector release includes:
- Selector Copilot with GenAI: GenAI combined with Selector Copilot provides instant access to more meaningful incident summaries, assists with troubleshooting, and enables automated remediation. Copilot helps democratize access to your operational telemetry, helping your team access insights quickly.
- Monitoring and observability: Collect and analyze telemetry from the network to your applications and everything in between. Empower your operations leaders to address tool sprawl and slash monitoring costs. Improve business outcomes with service-level objectives (SLOs) and service-level agreements (SLAs).
- Root cause analysis: Identify the root cause of an incident through an innovative causal approach, fast-tracking incident investigation and remediation. Additionally, an integrated feedback loop solicits user input, helping to improve correlations and produce more actionable notifications.
- Digital twin: With Selector, build and leverage digital representations of the network and IT infrastructure. Visualize traffic flows during routing changes and ensure a seamless client experience with improved capacity planning.
Also, in this release, watch for Selector in the Google Cloud Marketplace in Q2. It will enable frictionless software procurement, simplified vendor management, streamlined pricing, and help burn down cloud commits.
Now, let’s dig deeper into each of these highlights.
Selector Copilot with GenAI
Offered as part of the Selector platform, Selector Copilot combines conversational AI with a natural/human language query mechanism. It enables your teams to use retrieval-augmented generation (RAG) to enrich and enhance responses with external data sources.
Let’s examine an Enterprise Wi-Fi Network use case to help you understand Selector Copilot’s powerful capabilities.
Use case: Enterprise Wi-Fi network
In this use case, the operator uses Selector Copilot to understand the status of a Wi-Fi network for an enterprise, such as a hospital, hotel chain, retail store, or bank. The operator starts with the prompt:
Why is the user experience in a Wi-Fi zone red?
They can then prompt answers to more specific questions:
- Is the signal-to-noise ratio (SNR) or signal strength indicator (RSSI) not within the permissible limits?
- Has the Dynamic Host Configuration Protocol (DHCP) Request, DNS Query, or Radius Authentication failed?
- Why did it fail?
Figure 1 shows this natural language query. Although not shown in this figure, Copilot also includes possible remediations.

Monitoring and Observability
With this release, Selector can not only act on top of existing tools, but can directly collect configuration, metric, event, and log telemetry with its native monitoring capabilities.
Selector supports over 500 integrations across networks, infrastructures, clouds, and applications. It also integrates seamlessly with legacy monitoring and observability solutions to provide comprehensive insights into the overall IT environment.
Once the data is collected, Selector leverages machine learning to detect and identify anomalies. It then suppresses the duplicate and non-actionable events and points towards the root cause of an incident, helping the team reduce mean time to detect (MTTD) and mean time to resolve (MTTR).
Root Cause Analysis
Causal machine learning helps customers identify related issues and events across multiple data sets to find the underlying root cause of an incident.
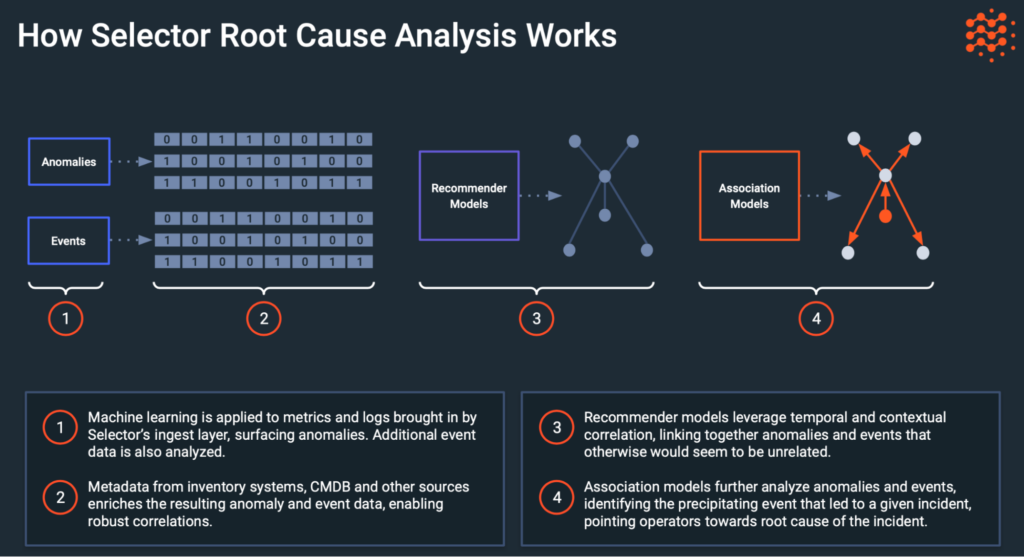
The process follows this flow:
- Machine learning is applied to metrics and logs brought in by Selector’s ingest layer, surfacing anomalies. Additional event data is also analyzed.
- Metadata from inventory systems, the configuration management database (CMDB), and other sources enrich the resulting anomaly and event data, enabling robust correlations.
- Recommender models leverage temporal and contextual correlation, linking anomalies for otherwise unrelated events.
- Association models further analyze anomalies and events, identifying the precipitating event that led to an incident and pointing operators toward the root cause.
Digital Twin
Create a digital twin of your network and IT infrastructure from the Selector platform. The digital twin feature provides visualization that enables the clients to:
- Increase revenue by creating offerings based on low latency and high bandwidth.
- Improve SLAs through simulated network failures and routing changes.
- Browse device capabilities, such as the number of IPv4 addresses a device can hold that impact the number of enterprises that can connect.
- Compare the impact of peak loads and design changes, minimizing the maintenance window.
Using Selector’s digital twin models to optimize your network/IT resources, you can improve your capital expenditures and reduce operating expenses.
Transformative Insights for Network and IT Ops
Tool sprawl has long plagued operations teams’ pursuit of actionable monitoring and observability. Selector’s unified monitoring and observability and AIOps platform bring disjointed multi-domain telemetry together. The net result is a single pane of glass that helps your team quickly understand what is happening across your IT environment.
Innovative GenAI assists with troubleshooting, automates incident remediation, and meaningfully summarizes incidents, helping the team keep your networks and infrastructure up and running. See Selector in action for yourself. Request a demo.


