Imagine you are a NOC lead, dealing with a network outage caused by a linecard failure. You are looking at potentially hundreds of incidents, starting from link flaps, protocol flaps, packet losses, application latencies, and many more. Compare that with having just a single incident in human-readable format, which lists all these impacts, highlighting the root cause as the linecard failure and suggested remediation.
Selector AI’s Intelligent Incident Management transforms incident handling by focusing on creating fewer, smarter incidents with complete context, drastically reducing Mean Time to Resolution (MTTR). This blog explores the core principles of this intelligent incident management approach.
Core Principles of Intelligent Incident Management
Data-Driven Correlations
Selector AI’s core strength resides in its data-driven correlation capabilities. The platform is designed to process a wide array of data, encompassing system logs, performance metrics, and events from existing monitoring tools. To manage this large influx of information effectively, Selector AI leverages machine learning algorithms. These algorithms play a crucial role in significantly decreasing the amount of data that human operators need to review manually, thereby improving efficiency and reducing cognitive load.
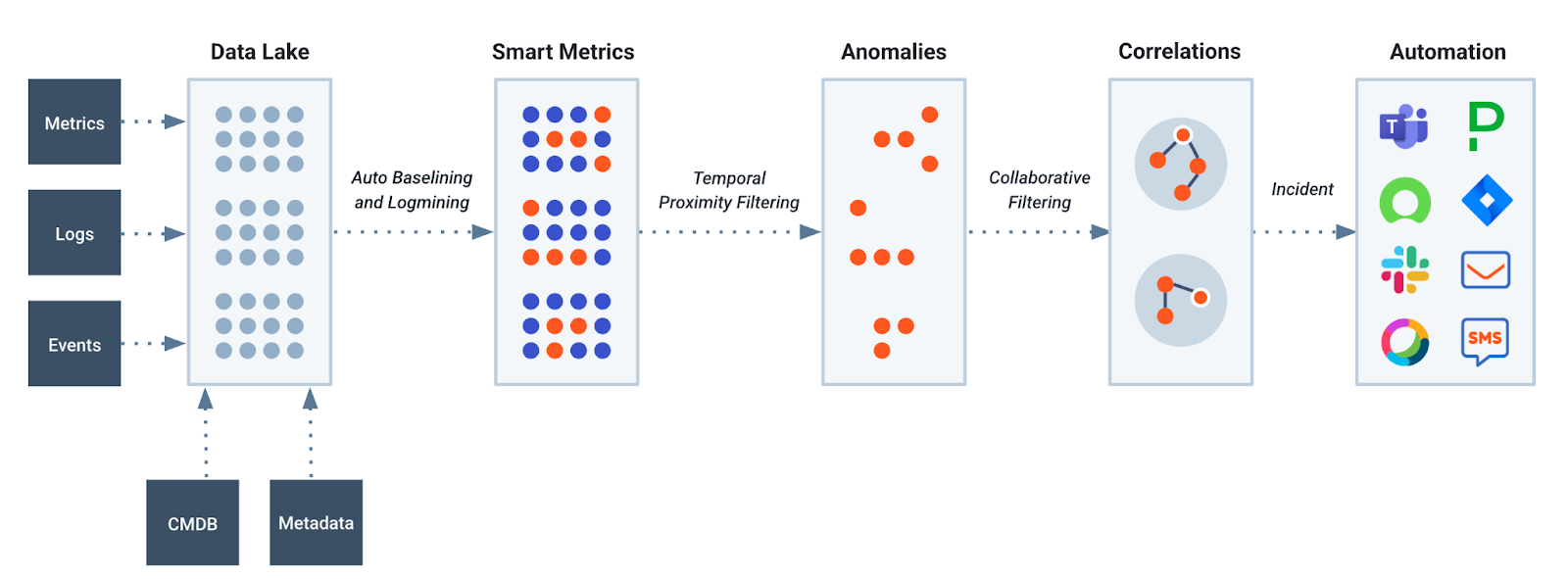
One of the key methods employed for data reduction and anomaly detection involves techniques such as baselining and log mining. By establishing normal operational patterns (baselining) and inferring from log entries (log mining), the models can pinpoint deviations or interesting data points. This reduction of surface area enables a more focused approach to identifying potential problems that may be interconnected within overwhelming volumes of raw data.
To identify these interconnecting anomalies, Selector AI utilizes collaborative filtering algorithms. These algorithms analyze data that has been enriched with additional metadata, allowing the system to create detailed representations or embeddings of the data points. These robust embeddings are instrumental in the engine’s ability to correlate anomalies that share some context.
These correlations are constructed as graphs that users can visualize to understand the model’s thought process for correlating. The graphs are then processed by the causation models, which infer the root cause from the events that constitute the graph. These graphs, coupled with root cause analysis, are used to generate consolidated incidents, providing users with a comprehensive understanding of problems rather than presenting a barrage of isolated incidents for each anomaly.
A typical correlated incident by Selector packs anywhere between 10 to 500 individual alerts.
LLM-Enhanced Incident Descriptions
We should not expect that the correlated content produced by the algorithms can be understood by the NOC users as is. This is where Large Language Models (LLMs) are leveraged to generate human-readable and actionable incident summaries, significantly enhancing communication and understanding. These summaries provide clear, concise descriptions of the problem, its potential impact, and recommended actions, which simplifies troubleshooting and decision-making for incident responders.
The example below shows how an LLM-enhanced version of correlated incident is presented,

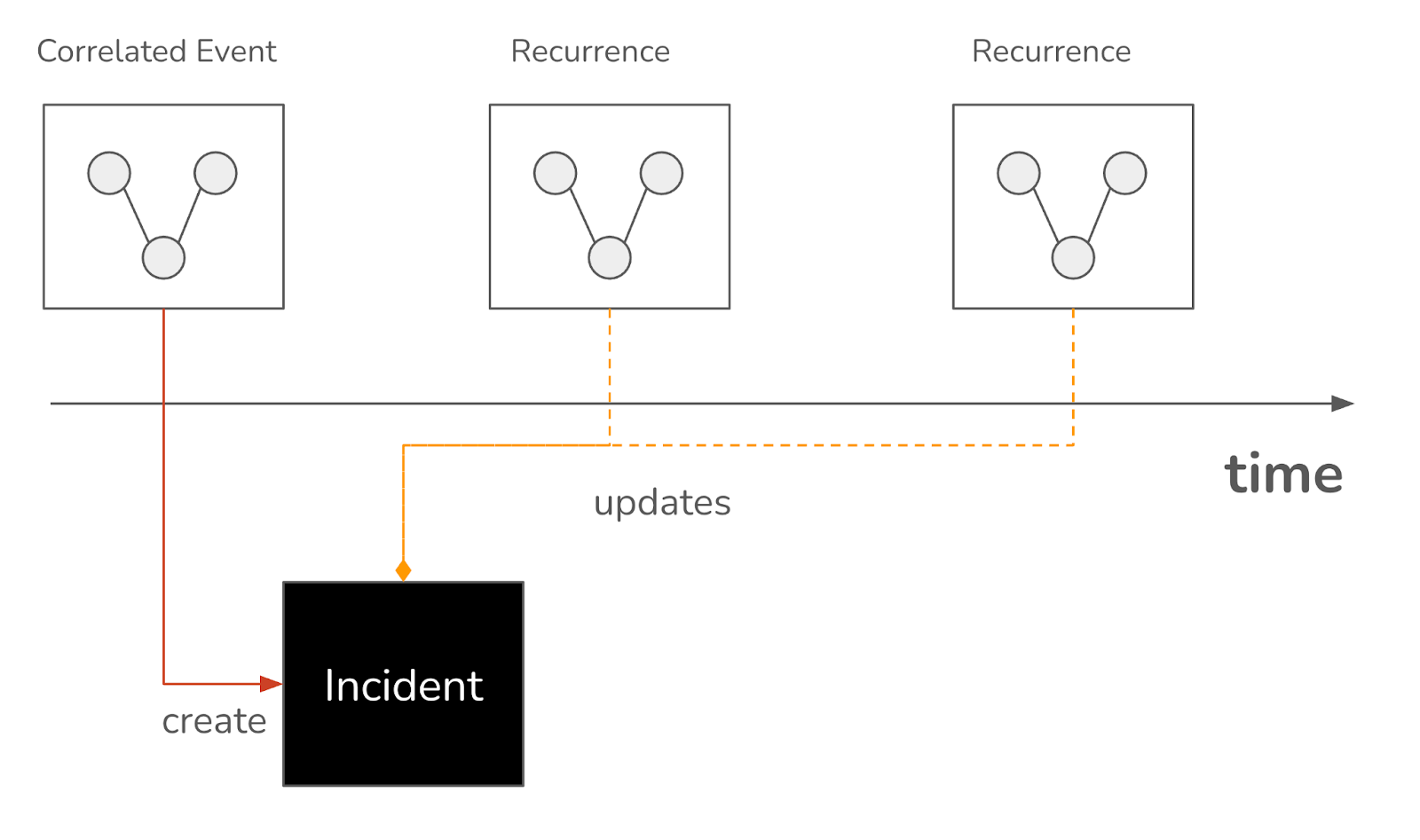
Stateful Incidents
Incidents are episodic in nature, meaning their effects can persist over a period of time until the root cause is resolved. Reducing the alerts alone is not sufficient. Instead, incidents should be treated as dynamic entities that gather context over time. Instead of viewing incidents as isolated events, Selector incident management tracks their evolution, accumulating relevant data and insights as it unfolds.
This provides a comprehensive picture of the incident’s lifecycle, facilitating more informed and effective resolution strategies, ultimately reducing the number of incidents to the number of unique episodes.
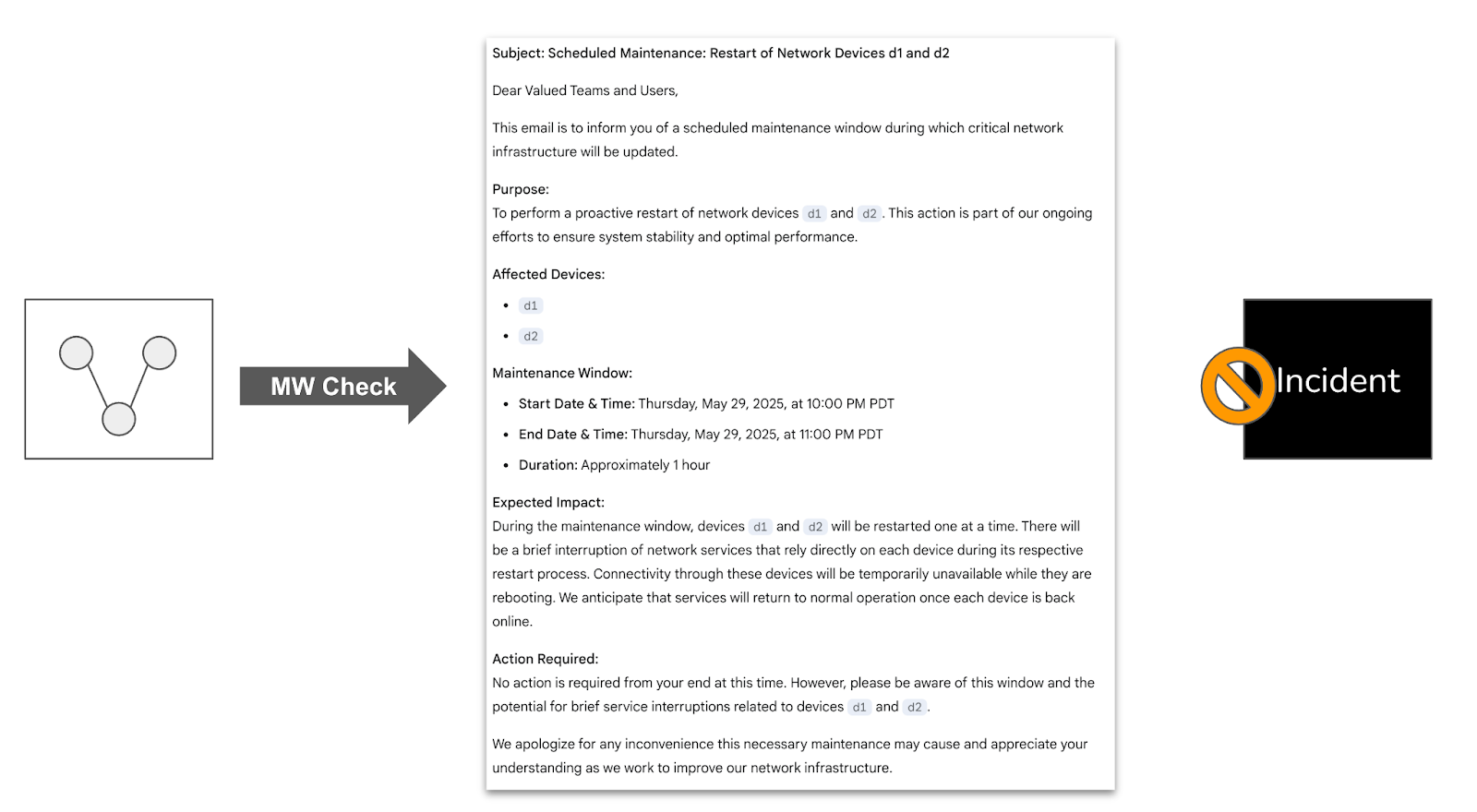
Maintenance Window Awareness
One practical aspect of incident management is the use of maintenance windows. Typically, incidents are created and then NOC teams close them as related to a planned change request, wasting a lot of man-hours. This is because maintenance windows are communicated out of band, via emails from the vendors.
Selector’s incident management approach is maintenance window aware. It can automatically recognize entities such as devices, circuit IDs, and time windows in unstructured email texts. When the engine detects a correlated event, it is verified against any active maintenance windows. Suppressing incident creation for matching events helps prevent a lot of noise and ensures that incident responders only focus on genuine issues.
Benefits of Intelligent Incident Management
| Benefit | Description |
|---|---|
| Reduced MTTR | Faster identification and resolution of incidents due to enhanced context and intelligent insights. |
| Fewer, Smarter Incidents | Filtering out noise and focusing on genuine issues leads to more efficient incident handling. |
| Enhanced Operational Efficiency | Automating alert correlation and providing actionable summaries, saving time and resources for IT teams. |
| Proactive Issue Detection | Identifying potential problems before they escalate into major incidents through the use of machine learning and analytics. |
| Improved Communication | Providing clear, human-readable incident descriptions that facilitate collaboration and understanding. |
Conclusion
Intelligent Incident Management, powered by Selector AI, represents a significant shift in how organizations handle incidents. By integrating machine learning, large language models (LLMs), and other advanced algorithms, Selector AI transforms reactive processes into proactive strategies, reduces operational overhead, and significantly improves service availability. Embracing this approach enables organizations to manage their IT environments more efficiently and effectively.
To stay up-to-date with the latest news and blog posts from Selector, follow us on LinkedIn or X and subscribe to our YouTube channel.