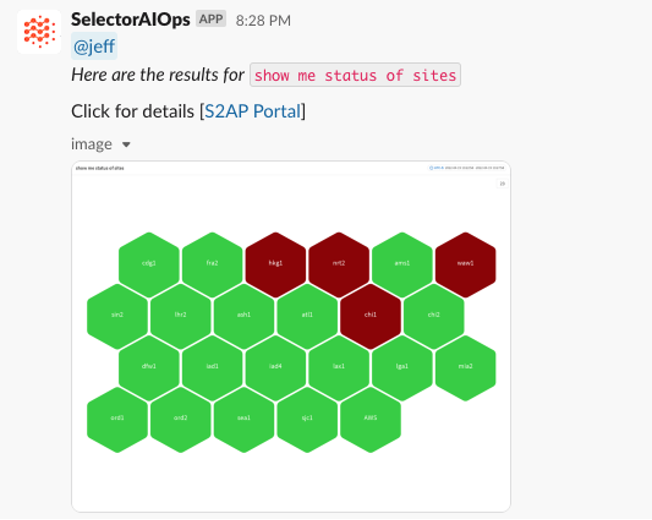
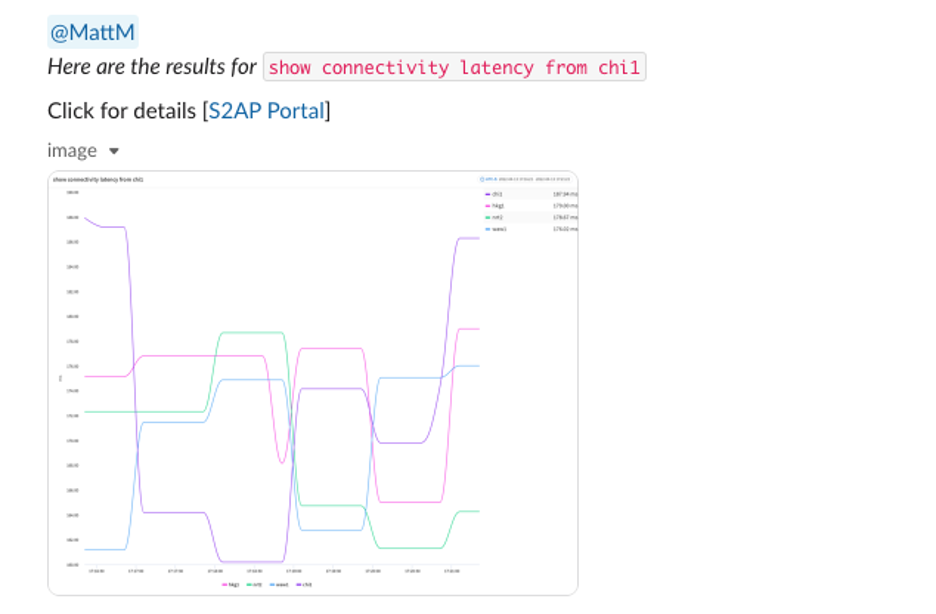
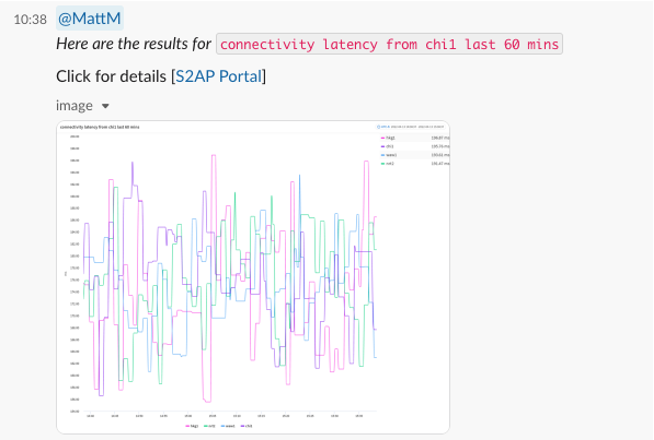
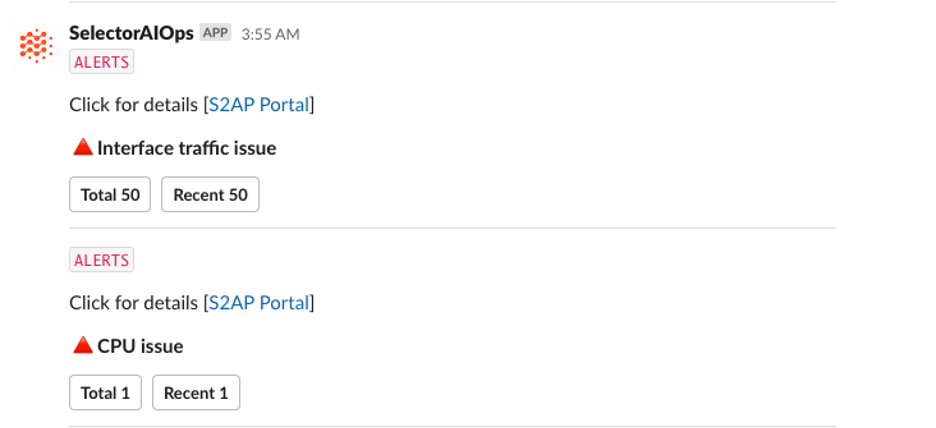
Cloud Observability Is Broken — Hybrid Operations Need a New Intelligence Model
Cloud adoption was supposed to simplify operations. Infrastructure would become programmable, scalability would become elastic, and distributed architectures would enable resilience at global scale. In practice, cloud has delivered extraordinary flexibility, but it has also introduced a level of operational complexity that traditional observability approaches were never designed to handle. Today’s enterprise environments are not simply “in the cloud.” They are hybrid ecosystems spanning multiple providers, regions, private infrastructure, edge locations, and interdependent network paths. Services operate across layers that are dynamically provisioned, continuously reconfigured, and often owned by different teams. Yet many organizations still approach cloud observability as if visibility alone is sufficient. It isn’t. The Visibility Paradox in Hybrid Cloud Environments Most enterprises have invested heavily in observability tooling. Metrics, logs, traces, flow telemetry, synthetic tests, and cloud-native monitoring capabilities generate unprecedented volumes of operational data. On paper, this should provide comprehensive visibility into system behavior. In reality, the opposite often occurs. Teams find themselves navigating fragmented dashboards and disjointed alert streams, each representing only a partial view of system state. A routing degradation may surface in network telemetry. A performance anomaly may appear in application metrics. A configuration drift may manifest in infrastructure logs. Individually, these signals are accurate. Collectively, they are ambiguous. This fragmentation creates what might be called the visibility paradox: more telemetry does not necessarily produce better operational insight. As hybrid architectures grow in scale and interdependence, outages rarely originate from a single component. They emerge from interactions between services, connectivity paths, and infrastructure layers. Understanding these interactions requires more than instrumentation. It requires context. Why Traditional Observability Models Fall Short Traditional observability frameworks were designed for relatively contained environments. They assume that system components can be monitored independently and that root cause can be inferred by analyzing deviations within each domain. Hybrid cloud environments invalidate these assumptions. Dependencies now extend across provider boundaries, network interconnects, and shared infrastructure layers. Performance degradations may originate in places where teams have limited visibility or control. Native cloud metrics may indicate healthy infrastructure even as user experience deteriorates along end-to-end delivery paths. This disconnect reflects a fundamental limitation: observability tools often analyze signals in isolation rather than preserving the relationships between them. As a result, operational teams must manually reconstruct context during incidents, slowing resolution and increasing risk. The operational burden shifts from interpreting system behavior to stitching together telemetry. Shifting From Observability to Operational Intelligence To address this challenge, organizations must evolve beyond traditional observability toward what might be described as operational intelligence. Operational intelligence is defined not by the quantity of telemetry available, but by the ability to understand how systems behave as interconnected ecosystems. It emphasizes correlation, dependency awareness, and causal reasoning over raw data collection. In hybrid cloud environments, this means: This shift fundamentally changes how incidents are investigated. Instead of reacting to alerts and validating assumptions manually, teams can operate with contextual awareness that guides decision-making from the outset. The Network Is the Missing Dimension of Cloud Operations One of the most persistent misconceptions in cloud operations is that infrastructure abstraction reduces the importance of network visibility. In reality, distributed cloud architectures make connectivity more critical than ever. Application performance often depends less on the health of individual resources and more on the reliability of the paths connecting them. Cross-region latency, interconnect failures, routing misconfigurations, and provider performance variability can all degrade service delivery even when underlying compute and storage resources appear stable. Without end-to-end path awareness, these issues are difficult to detect and diagnose. Operational intelligence frameworks address this gap by integrating network telemetry into broader observability models. By preserving path-level context alongside infrastructure and application signals, teams gain a more accurate representation of service health. This integrated perspective is essential for achieving true resilience in hybrid environments. Rethinking Capacity, Resilience, and Provider Strategy Hybrid cloud complexity also introduces new challenges in capacity planning and resilience engineering. Decisions about resource allocation, traffic routing, and provider selection increasingly depend on dynamic performance characteristics rather than static architectural assumptions. Operational intelligence enables more informed decision-making by analyzing utilization patterns and performance trends across regions and providers. Organizations can identify inefficiencies, anticipate bottlenecks, and optimize infrastructure investments based on empirical insights rather than reactive adjustments. Similarly, comparative visibility into provider performance supports more sophisticated resilience strategies. Enterprises can diversify critical service paths, mitigate dependency risks, and adapt to changing conditions with greater confidence. In this context, observability becomes a strategic capability rather than a purely technical one. The Future of Cloud Operations Is Context-Driven Hybrid cloud environments will continue to grow in scale and complexity. Emerging paradigms such as multi-cloud orchestration, edge computing, and AI-driven services will introduce additional layers of interdependence. Operational success will increasingly depend on the ability to understand system dynamics holistically. Organizations that remain reliant on fragmented observability models may find themselves constrained by reactive workflows and prolonged incident resolution cycles. Those that adopt intelligence-driven approaches will be better positioned to maintain service reliability and support innovation. The evolution from observability to operational understanding represents a broader shift in how enterprises manage digital infrastructure. It reflects a recognition that modern systems behave less like collections of components and more like interconnected ecosystems. In such environments, context is not a luxury. It is the foundation of effective operations. Stay Connected Selector is helping organizations move beyond legacy complexity toward clarity, intelligence, and control. Stay ahead of what’s next in observability and AI for network operations: